Instalación de Spark y "Hola Mundo" en Pyspark
El objetivo de este tutorial es mostrar el paso a paso para la instalación de un ambiente Spark (incluyendo Pyspark) en Windows 10/11 utilizando WSL, y la creación de un primer ejemplo sencillo de su utilización.
Instalación de Ubuntu sobre WSL
- Abrir Características de Windows y habilitar las siguientes:
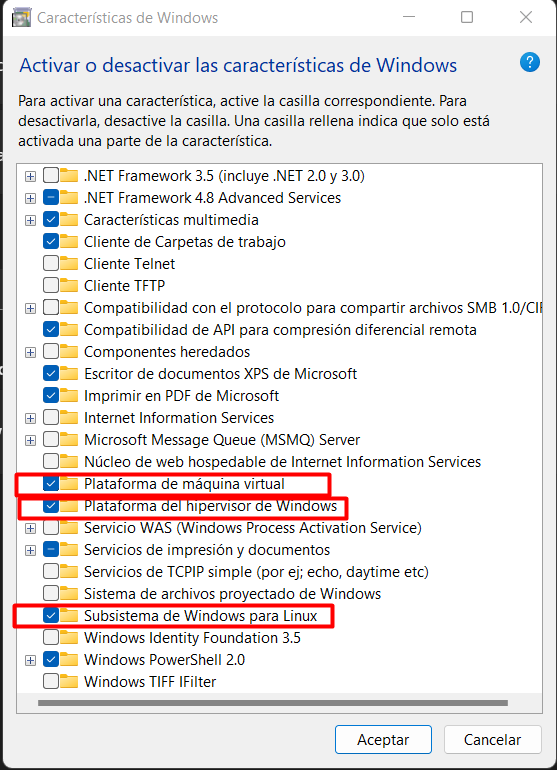
Luego de aceptar, se solicitará reiniciar al sistema.
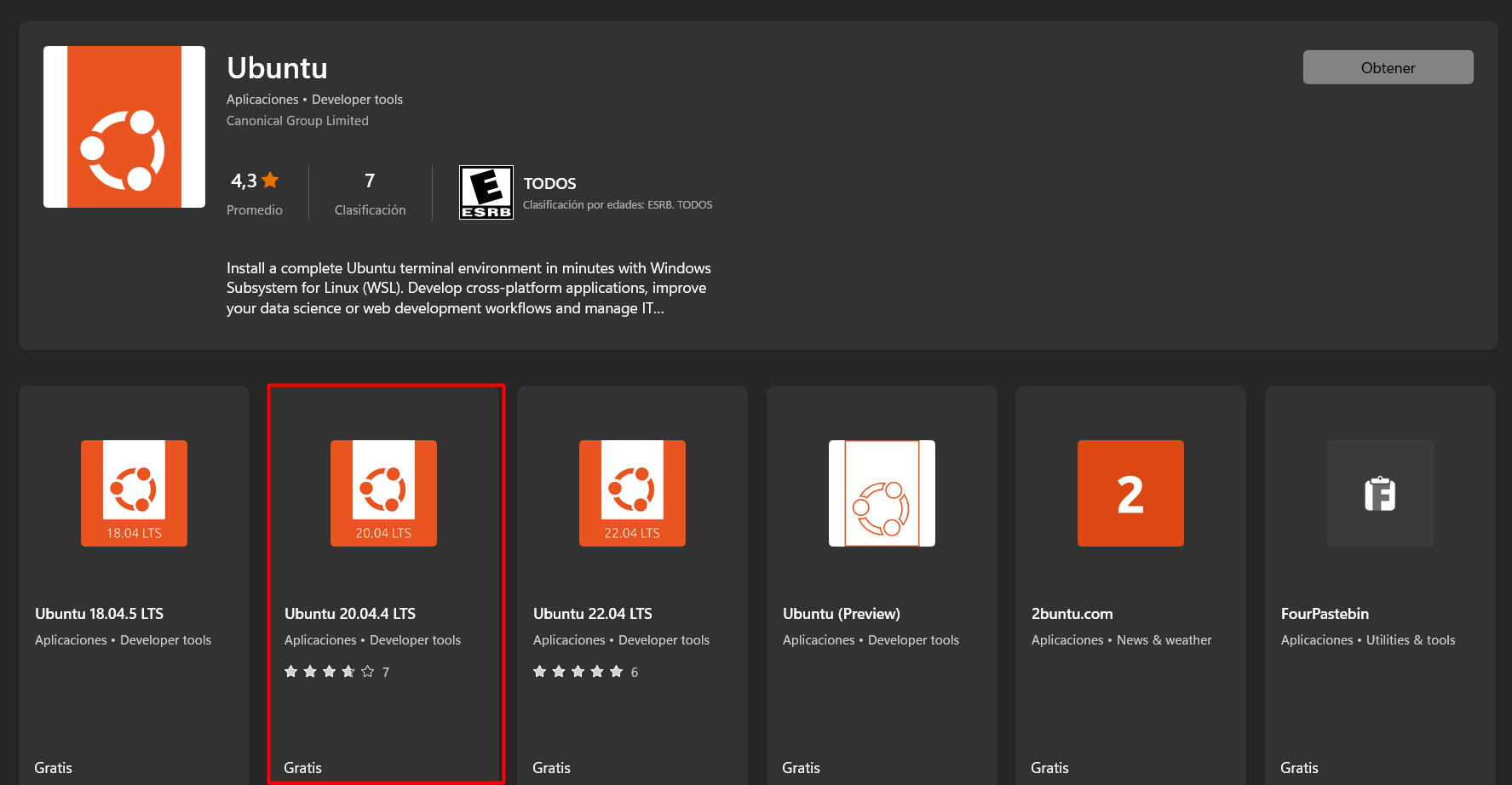
- En Windows Store buscar Ubuntu e instalar la versión 20.04.4 LTS
Al terminar la instalación y abrir Ubuntu aparecerá el siguiente error:
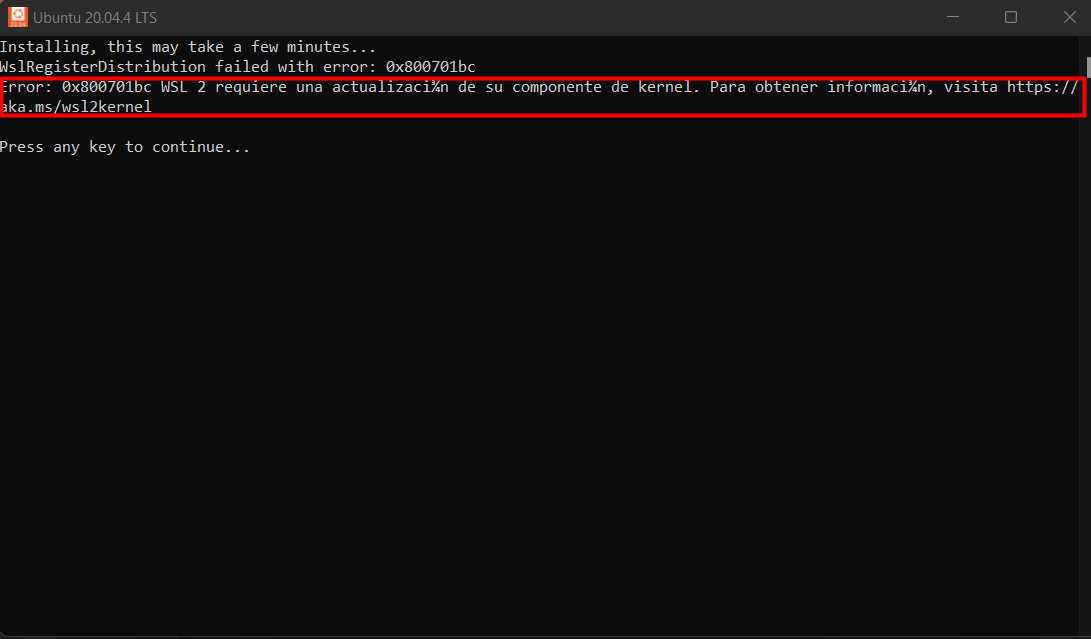
- Abrir la página http://aka.ms/wsl2kernel y descargar el siguiente archivo:
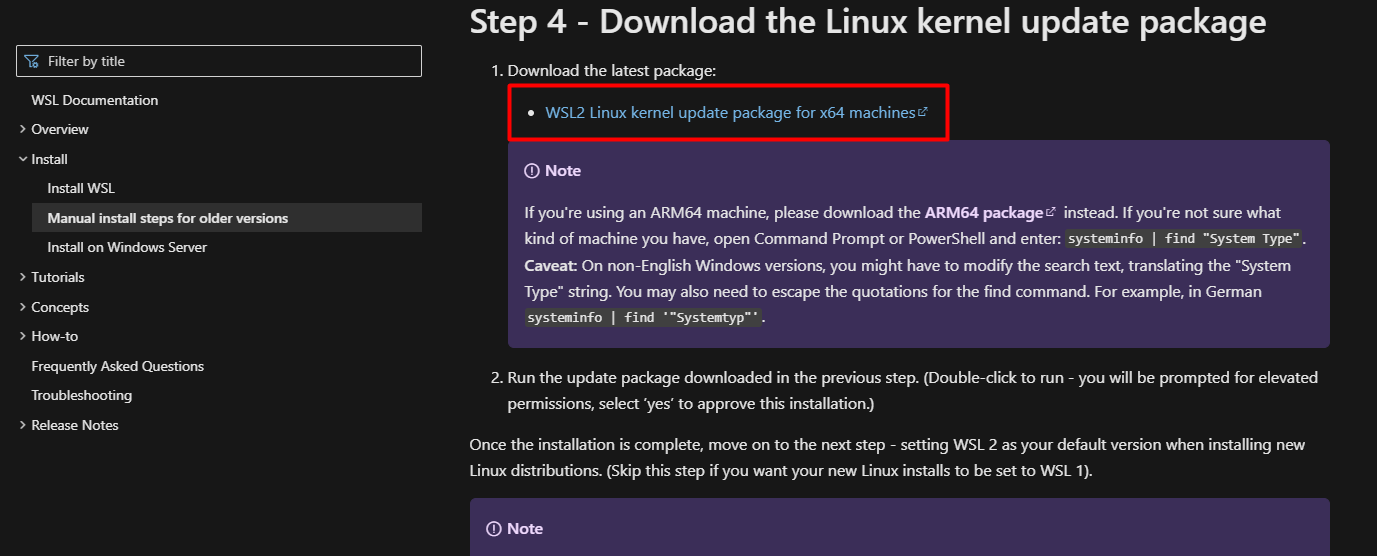
Luego de instalarlo, volver a lanzar Ubuntu. En este punto instalarán algunas actualizaciones y a continuación pedirá definir el usuario y la contraseña root:
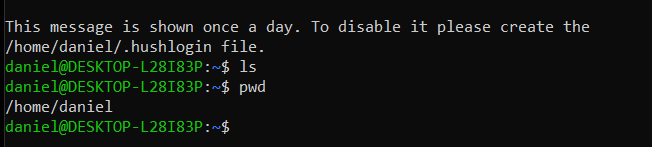
Se puede validar que la instalación este correcta utilizando los comandos ls y pwd:
Salir de ubuntu con exit
- Iniciar de nuevo Ubunto y sin cerrarlo abrir una consola de Power Shell, en está última utilizar el comando
wsl -l -vpara ver que versión de WSL se esta corriendo por defecto:
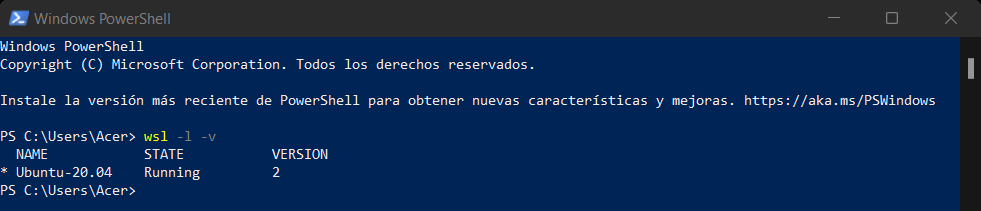
En caso que sea la versión 1 escribir wsl --set-default-version 2:

Cerrar Ubuntu para aplicar los cambios.
Instalación de Spark
Luego de tener correctamente congifurado el sistema operativo, se procede a instalar Spark mediante los siguientes comandos:
- Actualizar CLI:
sudo apt update -y
Pedirá la contraseña previamente definida para el usuario root.
- Instalar Java:
sudo apt install default-jre
En todos los momentos en los que pida confirmación, está se da con Y
-
Instalar el JRE:
sudo apt install openjdk-11-jre -
Instalara la JDK:
sudo apt install openjdk-11-jdk
En este punto se puede validar la versión instalada de Java con el comando:
java –version

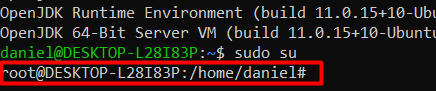
- Ingresar en modo superusuario:
sudo su
-
Crear carpeta de instalación:
mkdir –p /opt/spark -
Ubicarse en esa carpeta:
cd /opt/spark -
Instalar wget:
sudo apt install wget -
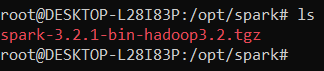
Descargar Spark:
wget https://dlcdn.apache.org/spark/spark-3.2.1/spark-3.2.1-bin-hadoop3.2.tgz(Este paso toma un tiempo considerable dependiendo del ancho de banda disponible)
Se puede verificar que el archivo se haya descargado en la carpeta correcta con ls
-
Descomprimir el archivo:
tar xvf spark-3.2.1-bin-hadoop3.2.tgz -
Salir de la carpeta actual con
cdy verificar que se encuentre un archivo.bashrcconls -al
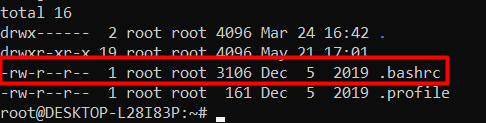
- Anañadir variables de entorno: Abrir nano con
nano .bashrc, ir hasta el final desplazandose con las flechas y conCrtl+Vpegar lo siguiente:
export SPARK_HOME=/opt/spark/spark-3.2.1-bin-hadoop3.2
export PATH=$PATH:$SPARK_HOME/bin
Salir de nano con Ctrl+X, guardar los cambios con Y y Enter
-
Validar la modificación del archivo:
cat .bashrc -
Recargar el archivo .bashrc:
source .bashrc
En este punto ya se tiene instalado Spark, se puede verificar con el comando spark-shell
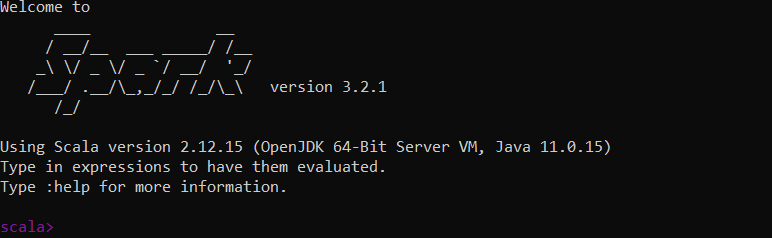
Al ejecutarlo se entrará en una consola de Scala
De la cual se sale con :q
Instalación de Pyspark
-
Instalar Python 3:
sudo apt install python3 -
Instalar PIP:
sudo apt install python3-pip
En todos los momentos en los que pida confirmación, esta se da con Y. Este paso toma algunos minutos.
- Anañadir variables de entorno: Abrir nano con
nano .bashrc, ir hasta el final desplazandose con las flechas y conCrtl+Vpegar lo siguiente:
export PYSPARK_PYTHON=/usr/bin/python3
Salir de nano con Ctrl+X, guardar los cambios con Y y Enter
-
Validar la modificación del archivo:
cat .bashrc -
Recargar el archivo .bashrc:
source .bashrc -
Instalar Pyspark: Mediante el comando
sudo pip install pyspark -
Recargar el archivo .bashrc:
source .bashrc
Ahora se puede validar la instalación con el comando pyspark
A diferencia de la ocasión anterios se ingresará a una consola Pthon:
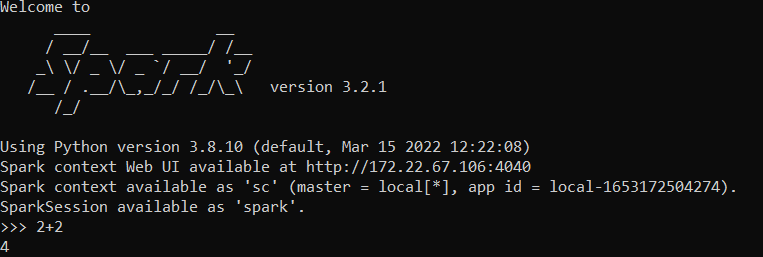
Ctrl+D para salir.
Integración con Visual Studio Code
Prerequisitos: Tener instalado:
- Anaconda
- Visual Studio Code con las extensiones:
- Python
- Jupyter
- Remote – WSL
- En la consola de Ubuntu ejecutar el comando
code .y agregar esta carpeta como segura:
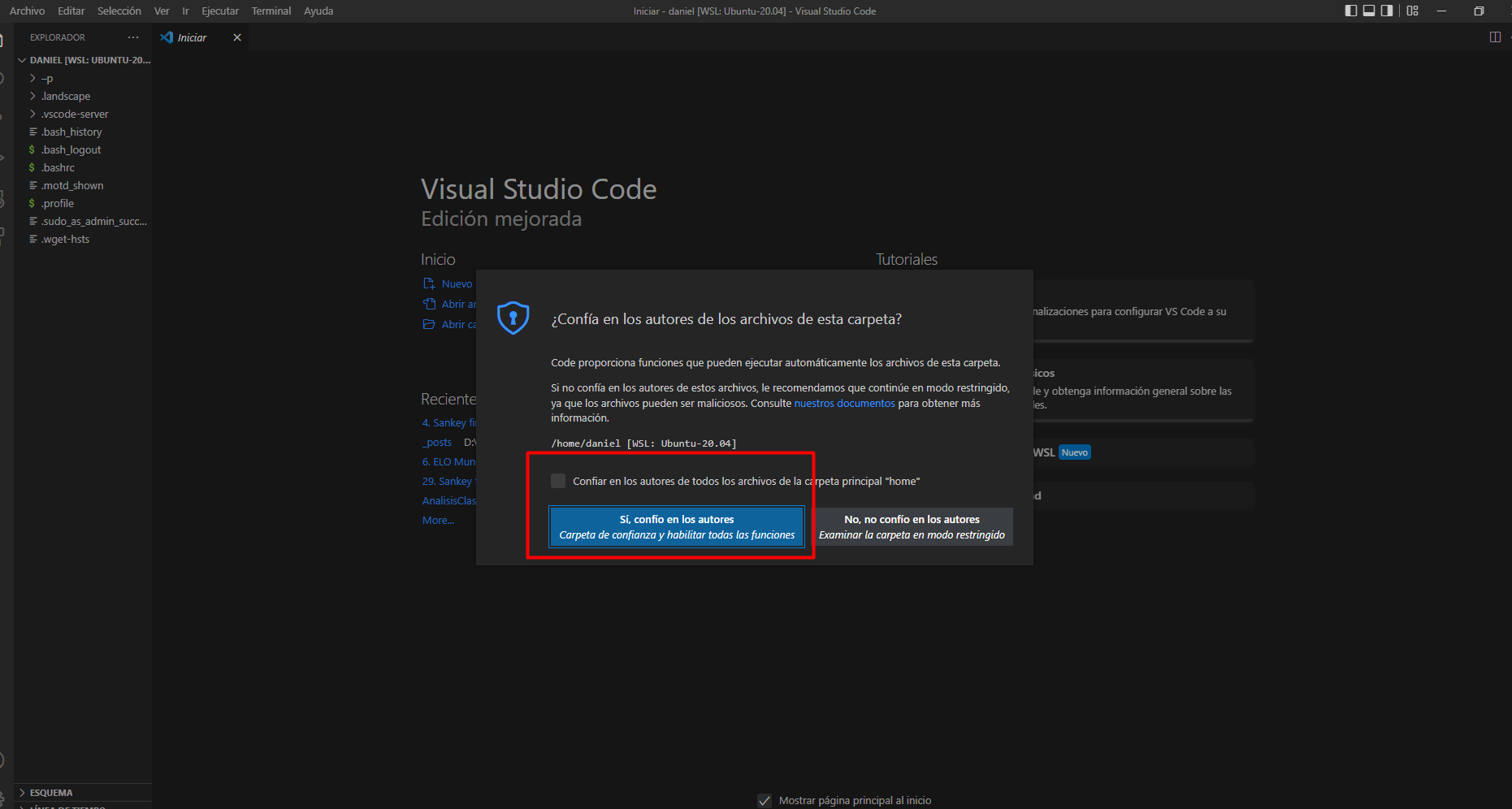
En caso que no aparezca la terminal, teclear Ctrl+Ñ. Se verá que se esta en el entorno linux y se tiene la consola corresponiente.
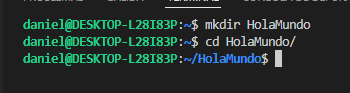
Crear un carpeta llamada HolaMundo y ubicarse en ella:
Integración con Visual Studio Code
En esta carpeta crear el archivo HolaMundo.ipynb e instalar las extensiones que recomiende.
En este archivo ya es posible utilizar todas las características de Pyspark, un demo se encuentra en el archivo Hola Mundo en Pyspark